
There are 3 types of resource allocation groups which can be configured in Doris DB:
| Resource Group Type | Doris DB Version | Use Case |
| Workload Group | v2.1+ REQ. Linux CGroup | Granular Hardware & Concurrency |
| Compute Group | v3.0+ | BE Server level only |
| Resource Group | v2.1.x or lower | Database or Tables on Host X |
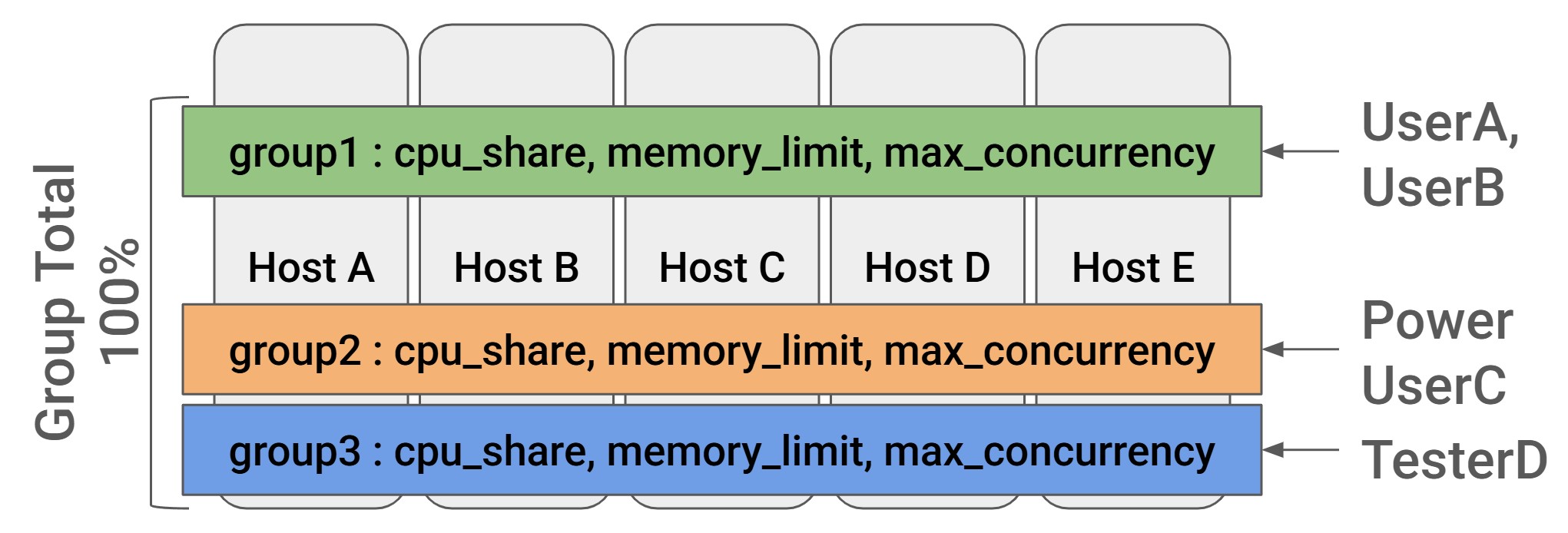
Workload Group
Introduction
Doris’s concurrency control and queuing mechanism is primarily implemented through workload groups. A workload group defines the resource usage limits for queries, including maximum concurrency, queue length, and timeout parameters. By properly configuring these parameters, the goal of resource management can be achieved.
Workload’s CPU management is based on CGroup. The memory and IO management functions of Workload Group are implemented internally by Doris and do not rely on external components. A “CGroup” in Linux stands for “control group,” which is a Linux kernel feature that allows administrators to manage and limit the resource usage (i.e. CPU) of a collection of processes by grouping them together and setting resource allocation rules for each group, providing fine-grained control over how system resources are distributed among different applications or users on a system.
Best Practice
The current Workload Group feature only supports deploying one BE (back-end server) instance on a single host.
After a machine is restarted, all configurations under the CGroup path will be cleared. To persist the CGroup configuration, you can use systemd to set the operation as a custom system service, so that the creation and authorization operations can be automatically performed each time the machine restarts.
The current queuing design does not take into account the number of FEs. The queuing parameters only take effect at the single FE (Front-end server) level. For example: In a Doris cluster, if a workload group is configured with max_concurrency=1: If there is 1 FE in the cluster, the workload group will allow only one SQL query to run at a time in the cluster; If there are 3 FEs in the cluster, the maximum number of SQL queries in the cluster could be 3.
Examples of when to use Workload Groups
BrokerLoad and S3Load are commonly used methods for large-scale data load. Users can first upload data to HDFS or S3, and then use BrokerLoad and S3Load to load data in parallel. To speed up the load process, Doris uses multi-threading to pull data from HDFS/S3, which can generate significant pressure on HDFS/S3, potentially making other jobs running on HDFS/S3 unstable.
To mitigate the impact on other workloads, the Workload Group’s remote IO limit feature can be used to restrict the bandwidth used during the load process from HDFS/S3. This helps reduce the impact on other business operations.
select * from information_schema.workload_groups;
or
show workload groups\G;The above commands will return all the configuration values of the workload groups on the system. Key config settings like: cpu_share, memory_limit (%), max_concurrency (queries), read_bytes_per_second (io), remote_read_bytes_per_second (io) …
Compute Group
Introduction
A Compute Group is a mechanism for physical isolation between different workloads since the new V3.0 storage-compute separation architecture.
Best Practice
Managing compute groups requires OPERATOR privilege, which controls node management permissions.
If the current user has not configured a default compute group, the existing system will trigger an error when performing data read/write operations. To resolve this issue, the user can execute the use @cluster command to specify the compute group used by the current context, or use the SET PROPERTY statement to set the default compute group.
SET PROPERTY 'default_compute_group' = '{clusterName}';
or
SET PROPERTY FOR {user} 'default_compute_group' = '{clusterName}';Examples of when to use Compute Groups
Instead of Workload Groups, Compute Groups are the easier way to allocate compute space to a particular user, as it operates at a high level i.e. per BE server.
Resource Group
Introduction
Using the older version 2.1 of Doris DB, a Resource Group is used to split or restrict access to data assets by department inside the same company. Or if the Doris DB system is provided as a data platform to several companies, it is used to segregate the data between companies, so that users from one site cannot access another’s company’s data.
Since version 3.0 can be deployed in decoupled mode (storage separate from compute) this grouping doesn’t make sense, as it can create replicas of tables per host. Also as the data is not stored on a BE host anymore (only cache), it will all be on the shared location (S3 / HDFS). We therefore recommend the use of ROLE based access to limit access to data assets.
Examples of when to use Resource Groups
Read-write isolation: A cluster can be divided into two Resource Groups, with an Offline Resource Group for executing ETL jobs and an Online Resource Group for handling online queries. Data is stored with 3 replicas, with 2 replicas in the Online Resource Group and 1 replica in the Offline Resource Group. The Online Resource Group is primarily used for high-concurrency, low-latency online data services, while large queries or offline ETL operations can be executed using nodes in the Offline Resource Group. This allows for the provision of both online and offline services within a unified cluster.
Isolation between different businesses: When data is not shared between multiple businesses, a Resource Group can be assigned to each business, ensuring no interference between them. This effectively consolidates multiple physical clusters into a single large cluster for management.
Isolation between different users: For example, if there is a business table within a cluster that needs to be shared among all three users, but it is desirable to minimize resource contention between them, we can create 3 replicas of the table, stored in 3 different Resource Groups, and bind each user to a specific Resource Group.
Full v3.0 Doris DB documentation here:
Leave a Reply