
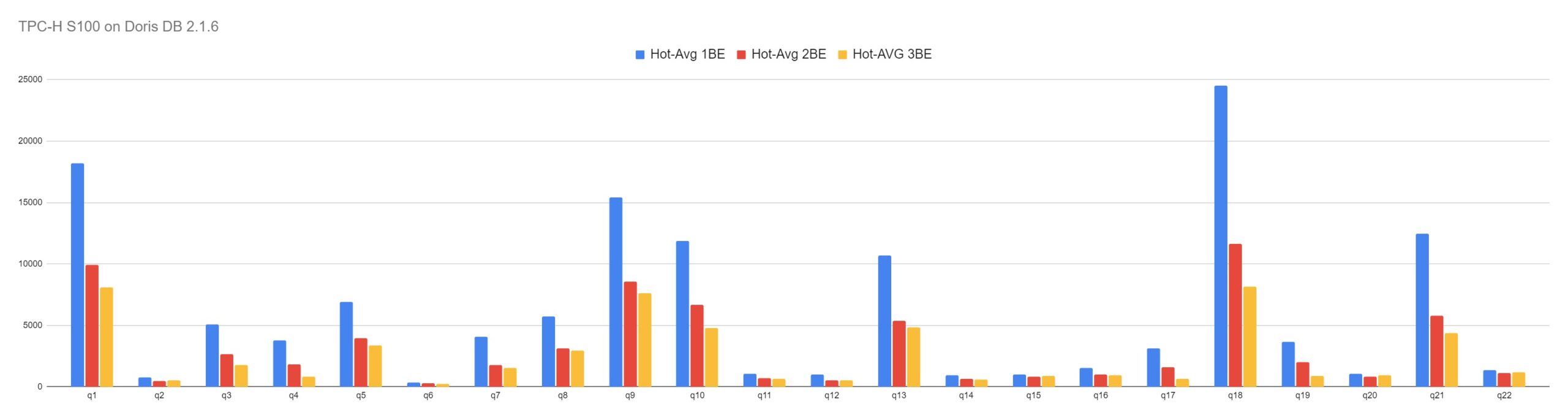
Doris DB can scale out data evenly across a cluster to increase performance and return query results faster. For longer running queries it nearly achieves proportional scalability.
For more information on the TPC-H SF100 source files of this test, please consult the documentation.
VeloDB cloud deployments offer elastic functionality for data warehouses, allowing for scalability and flexibility to handle fluctuating data loads. This means that resources can be adjusted to meet changing demands, reducing costs and improving efficiency. For example, a data warehouse can automatically scale up during peak processing times and scale down when processing is low. This ensures that the data warehouse can handle the workload without sacrificing performance or reliability.

The above chart shows tests with the same dataset, but balanced out across 1, 2 and 3 Backend Servers (each 8vCPU, 32GB, 200GB HDD)
Naturally data footprint of a company grown over time and additional servers are needed, not just for space, but also processing power. Adding another backend server into a Doris DB cluster is easy as entering the following command as root:
ALTER SYSTEM ADD BACKEND “192.168.1.19:9050”
( ALTER SYSTEM ADD BACKEND “<IP Address>:<port>” )
Once the additional server is known in the FE cluster, it automatically starts balancing out the data to the additional server. So if there were 2 backend servers, it now divides the whole data pool by 3 and redistributes it, all servers will notice changes.
This is the state just after the 3rd Backend server was added. No space is used on it yet and the 2 original servers both carried 15GB of data.

Then after about 10-15mins the data has been redistributed and all servers now have about 10GB each.

If you would like to find out more about test-driving Doris DB using your own dataset please contact us.